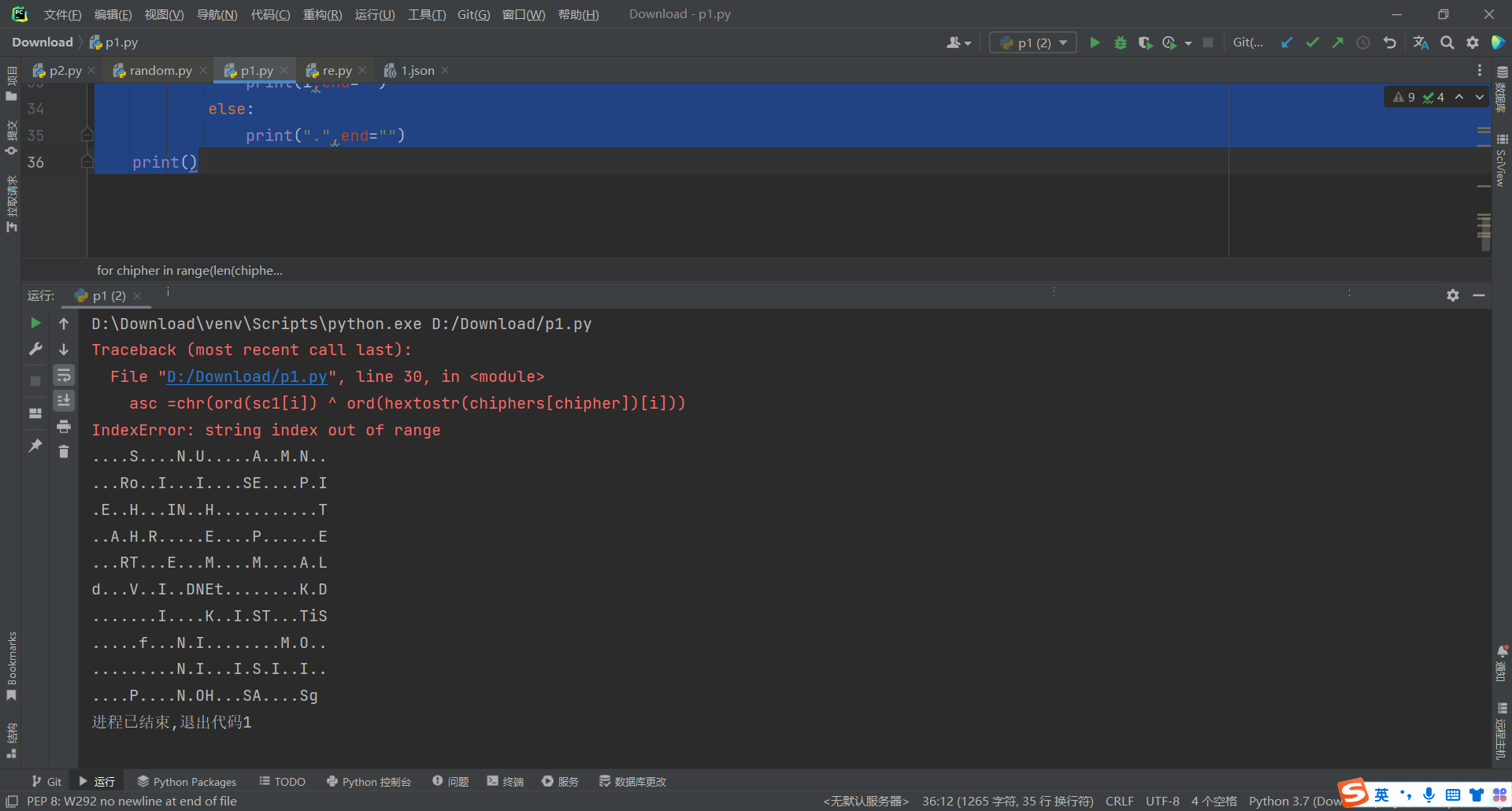
s2 = hextostr(c2) sc1 = hextostr(c1) for chipher inrange(len(chiphers)): if chipher == 0: continue for i inrange(len(sc1)): asc =chr(ord(sc1[i]) ^ ord(hextostr(chiphers[chipher])[i])) for i in asc: if i in loca: print(i,end="") else: print(".",end="") print()
import Crypto.Util.strxor as xo import libnum, codecs, numpy as np
defisChr(x): iford('a') <= x and x <= ord('z'): returnTrue iford('A') <= x and x <= ord('Z'): returnTrue returnFalse
definfer(index, pos): if msg[index, pos] != 0: return msg[index, pos] = ord(' ') for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(' ')
dat = []
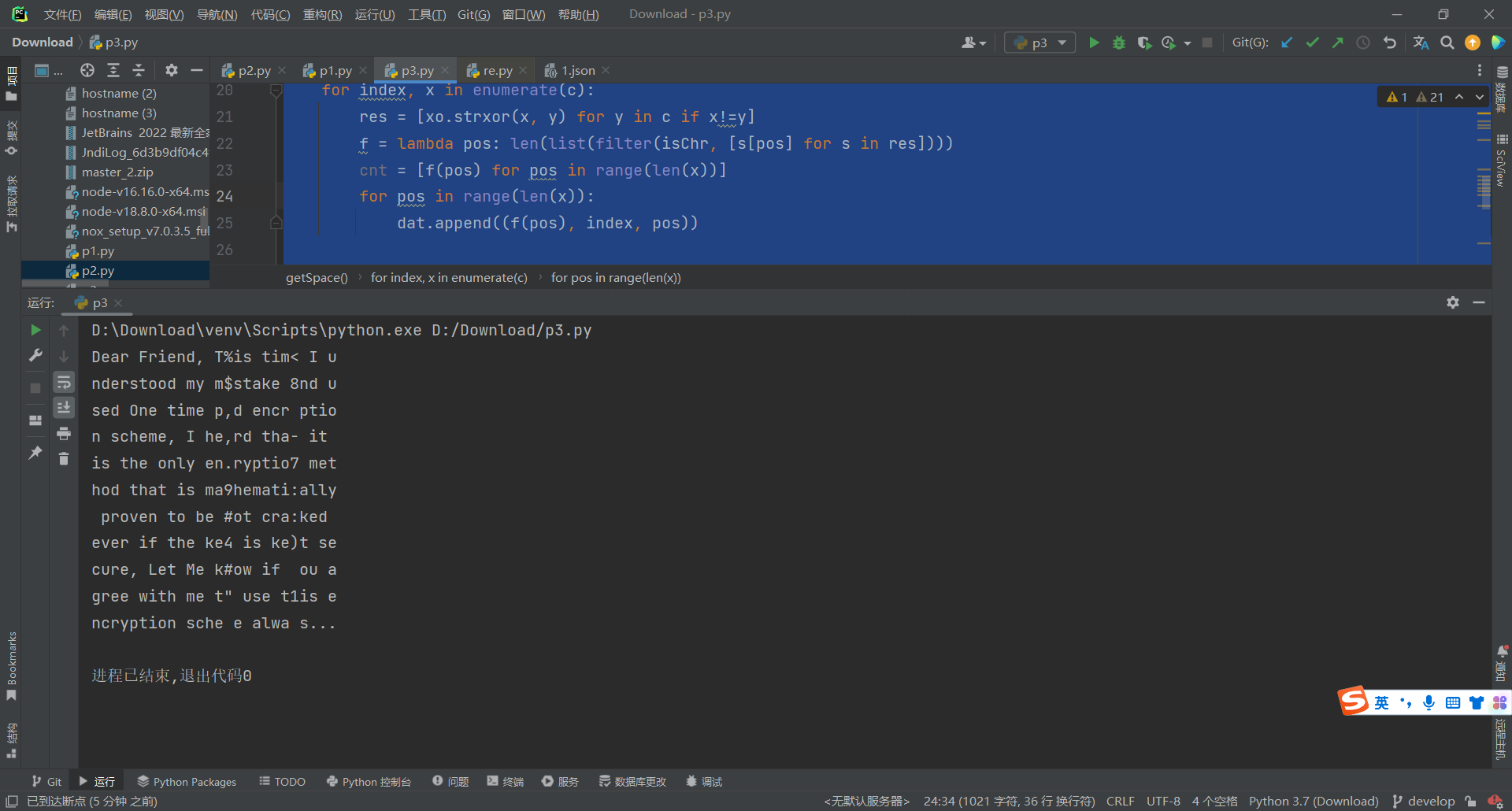
defgetSpace(): for index, x inenumerate(c): res = [xo.strxor(x, y) for y in c if x!=y] f = lambda pos: len(list(filter(isChr, [s[pos] for s in res]))) cnt = [f(pos) for pos inrange(len(x))] for pos inrange(len(x)): dat.append((f(pos), index, pos))
c = [codecs.decode(x.strip().encode(), 'hex') for x inopen('Problem.txt', 'r').readlines()]
msg = np.zeros([len(c), len(c[0])], dtype=int)
getSpace()
dat = sorted(dat)[::-1] for w, index, pos in dat: infer(index, pos)
print('\n'.join([''.join([chr(c) for c in x]) for x in msg]))
脚本太复杂了 看不太懂
这里需要修正一下 将k#now 修复成know 把 alwa s 修复成 always
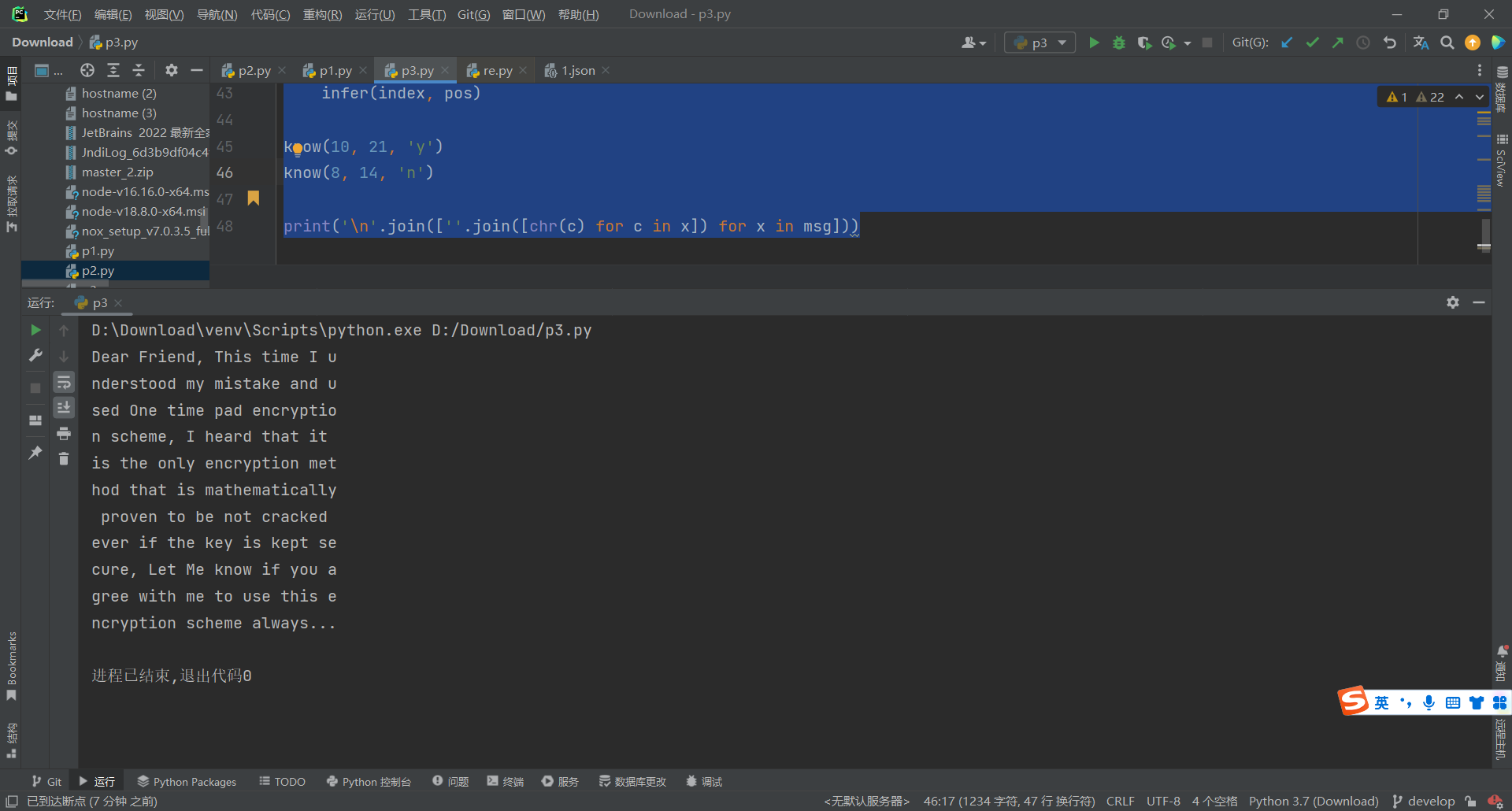
defknow(index, pos, ch): msg[index, pos] = ord(ch) for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(ch)
know(10, 21, 'y') know(8, 14, 'n')
print('\n'.join([''.join([chr(c) for c in x]) for x in msg]))
import Crypto.Util.strxor as xo import libnum, codecs, numpy as np
defisChr(x): iford('a') <= x and x <= ord('z'): returnTrue iford('A') <= x and x <= ord('Z'): returnTrue returnFalse
definfer(index, pos): if msg[index, pos] != 0: return msg[index, pos] = ord(' ') for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(' ')
defknow(index, pos, ch): msg[index, pos] = ord(ch) for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(ch)
dat = []
defgetSpace(): for index, x inenumerate(c): res = [xo.strxor(x, y) for y in c if x!=y] f = lambda pos: len(list(filter(isChr, [s[pos] for s in res]))) cnt = [f(pos) for pos inrange(len(x))] for pos inrange(len(x)): dat.append((f(pos), index, pos))
c = [codecs.decode(x.strip().encode(), 'hex') for x inopen('Problem.txt', 'r').readlines()]
msg = np.zeros([len(c), len(c[0])], dtype=int)
getSpace()
dat = sorted(dat)[::-1] for w, index, pos in dat: infer(index, pos)
know(10, 21, 'y') know(8, 14, 'n')
print('\n'.join([''.join([chr(c) for c in x]) for x in msg]))
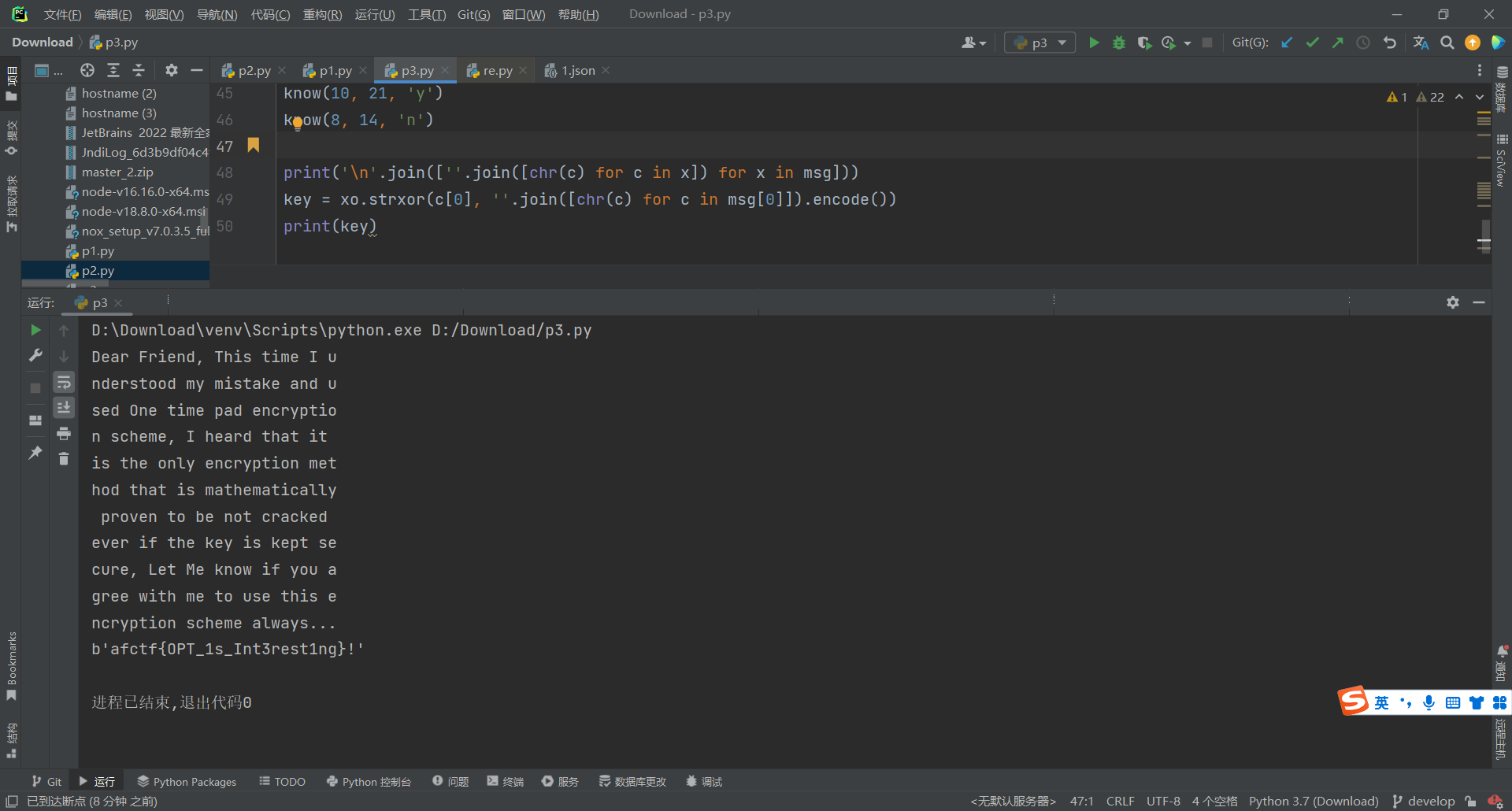
接着需要C1 ⊕ M1 = key
import Crypto.Util.strxor as xo import libnum, codecs, numpy as np
defisChr(x): iford('a') <= x and x <= ord('z'): returnTrue iford('A') <= x and x <= ord('Z'): returnTrue returnFalse
definfer(index, pos): if msg[index, pos] != 0: return msg[index, pos] = ord(' ') for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(' ')
defknow(index, pos, ch): msg[index, pos] = ord(ch) for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(ch)
dat = []
defgetSpace(): for index, x inenumerate(c): res = [xo.strxor(x, y) for y in c if x!=y] f = lambda pos: len(list(filter(isChr, [s[pos] for s in res]))) cnt = [f(pos) for pos inrange(len(x))] for pos inrange(len(x)): dat.append((f(pos), index, pos))
c = [codecs.decode(x.strip().encode(), 'hex') for x inopen('Problem.txt', 'r').readlines()]
msg = np.zeros([len(c), len(c[0])], dtype=int)
getSpace()
dat = sorted(dat)[::-1] for w, index, pos in dat: infer(index, pos)
know(10, 21, 'y') know(8, 14, 'n')
print('\n'.join([''.join([chr(c) for c in x]) for x in msg])) key = xo.strxor(c[0], ''.join([chr(c) for c in msg[0]]).encode()) print(key)

 微信
微信 支付宝
支付宝
